
在明確定義出商業目標之後,接下來就可以開始著手準備資料啦!資料的準備通常分為以下幾個步驟:
你可能會想:「蒐集、標記和處理資料這麼基本的事情,我天天都在做,有什麼困難的嗎?」
儘管這些是最基本的步驟,然而在學生時期或是進行 side projects 時,通常只會使用幾份資料集,每個資料集的量不大,而且蒐集完成後資料就是固定的。而在業界,資料規模通常非常龐大,並且會隨著用戶每天的操作不斷更新。此外,資料往往不只供你一個人使用,還需要和同部門甚至其他部門的同事共享,使得如何有效蒐集與管理資料成了一大挑戰。
聽到這裡,是不是覺得準備資料比想像中更複雜呢?今天我們就來看看有什麼值得注意的細節吧!
稍早有提到,在業界建立模型時,資料的來源可能會不斷更新,甚至有多個不同版本。如同程式碼需要版本控制一樣,數據也需要版本控制,以便追蹤數據的變化歷史,並在需要時回滾到之前的版本。
可以使用數據版本控制工具,如 DVC、MLflow、Delta Lake等,來管理數據的版本。另外,要記得保存每個版本的 meta-data,知道資料的來源,以及紀錄 lineage(下游資料是經由哪些處理步驟、是結合哪些上游資料而得的)。這些資訊有助於在建立模型之後的錯誤分析(error analysis),幫助追溯問題根源。
資料標記的一致性是建立資料集非常重要的一環。然而,由於每個標記者對類別定義的理解可能不同,容易出現不一致的標記情況。
小規模資料集:資料量較少時,標記的一致性非常重要,因為少量的錯誤標記就有可能會嚴重影響模型的表現。不過,也由於資料較少,通常可以逐一檢查樣本,標記者之間也能夠方便地討論標記準則。
大規模資料集:當資料量龐大時,儘管可能會有一些不一致的標記或雜訊,不過由於數據量夠多,還是能夠平均掉這些雜訊,找到有意義的 patterns。此時更強調數據處理流程的可靠性,確保資料收集與儲存的過程準確無誤。
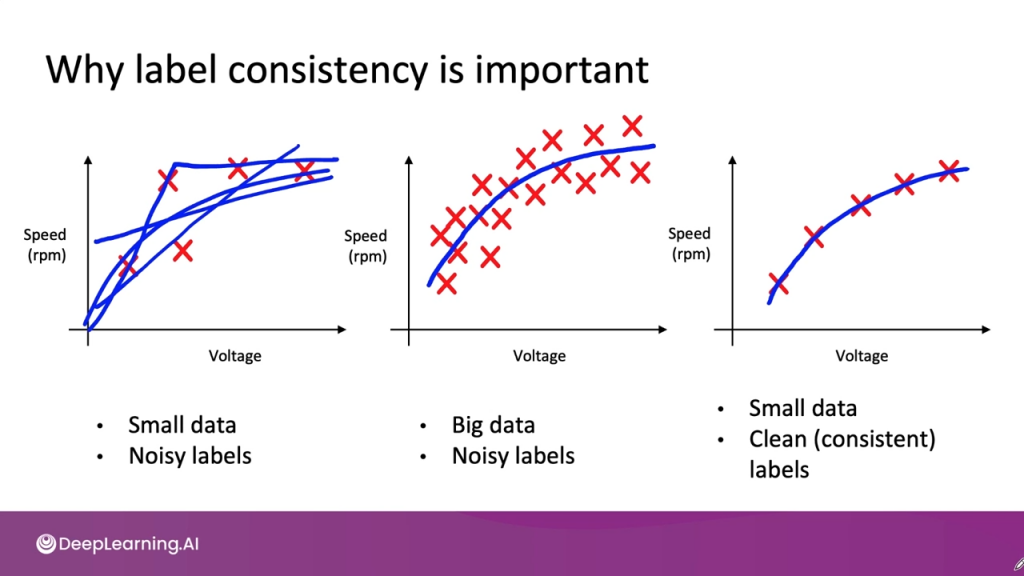
圖片來源:Machine Learning in Production | DeepLearning.AI
資料可以分為兩種類型,這兩種資料面臨的問題不同:
結構化資料(Structured Data):結構化資料通常以表格形式存在,難以進行 data augmentation,且通常難以獲取更多數據,也不易進行人工標記。
另外,輸入特徵有時可能無法提供足夠的資訊,以建立出一個好的模型,需要額外進行資料選擇和特徵工程(feature engineering)。
非結構化資料(Unstructured Data):例如聲音、文字或圖片等資料,若非結構化資料數量不足,可以透過 data augmentation 來增加數據量,或是進行人工標記來提升資料品質。
為什麼結構化資料難以進行 data augmentation 以及難以蒐集更多數據呢?讓我們來看一個範例。
範例資料:客戶購物數據
| 客戶ID | 年齡 | 性別 | 購物次數 | 購物金額 | 地區 |
|---|---|---|---|---|---|
| 1001 | 30 | 男 | 15 | $300 | 台北 |
| 1002 | 45 | 女 | 8 | $200 | 高雄 |
| 1003 | 28 | 男 | 12 | $150 | 台中 |
| 1004 | 50 | 女 | 20 | $500 | 台北 |
Data Augmentation
在圖片或語音資料中,可以透過圖片的旋轉縮放、增加噪音等方式進行 data augmentation,以增加訓練資料的數量。但是對於表格數據(如客戶購物數據),很難對單個欄位進行這樣的擴增,因為我們不知道要如何修改才不會導致不真實的結果。
難以獲取更多數據
表格中的每一筆數據都需要實際的觀察或記錄。比如一個新客戶的行為,需要從真實的購買行為中收集到更多數據,而不像非結構化資料一樣可以透過旋轉、縮放或增加噪音來合成新數據。因此,如果想要增加數據需要投入更多的人力和時間來收集和整理,成本較高。
難以進行人工標記
結構化資料通常是從真實用戶行為中蒐集而來,例如購物次數、購物金額等數據是來自於交易記錄,不需要也無法進行像是圖片或語音數據那樣的人工標記,因為我們無法從這種表格數據中判斷出如顧客的購物偏好等資訊。
處理資料時通常需要建立 pipelines,從原始數據(raw data)經過資料清理(data cleaning)再到建模(modeling)。整個資料的準備過程可以是一個獨立的 data pipeline,也可以由多個小 pipeline 組成。要特別注意的是,在開發過程中使用的資料前處理腳本(data pre-processing scripts),要確保可以在 production 環境中被複製並應用。
稍早有提到,在業界建立模型時,資料的來源可能會不斷更新,甚至有多個不同版本。如同程式碼需要版本控制一樣,數據也需要版本控制,以便追蹤數據的變化歷史,並在需要時回滾到之前的版本。
可以使用數據版本控制工具,如 DVC、MLflow、Delta Lake等,來管理數據的版本,並記錄每個版本的 meta-data,例如數據來源和處理流程等等。
由於可能會不斷地有新的數據湧入,進行數據測試有助於確保數據的品質和一致性。可以設計和執行各種數據測試,例如:
數據驗證測試:驗證數據是否符合預期的格式、範圍和條件。
數據一致性測試:檢查數據在不同數據來源和處理階段的一致性。
數據分佈測試:監控數據分佈的變化,檢查是否有數據漂移(data drift),也就是模型訓練數據和實際使用數據分佈差異過大,影響模型表現。
講了這麼多,有沒有發現資料管理其實比原本想像的還要複雜許多呢?你會不會好奇擁有成千上萬則影片的 Netflix 又要如何管理這些影片呢?我們會在之後的系列文中介紹 Netflix 實際在管理數據的資料平台,請敬請期待哦!
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
如果有任何問題想跟我聊聊,或是想看我分享的其他內容,也歡迎到我的 Instagram(@data.scientist.min) 逛逛!
我們明天見!
